Overview
The overall performance of a service is directly linked, among other things, to its ability to tolerate failures. This aspect of an application/software can be tested by deliberately injecting random faults and failures into the application & its underlying infrastructure.
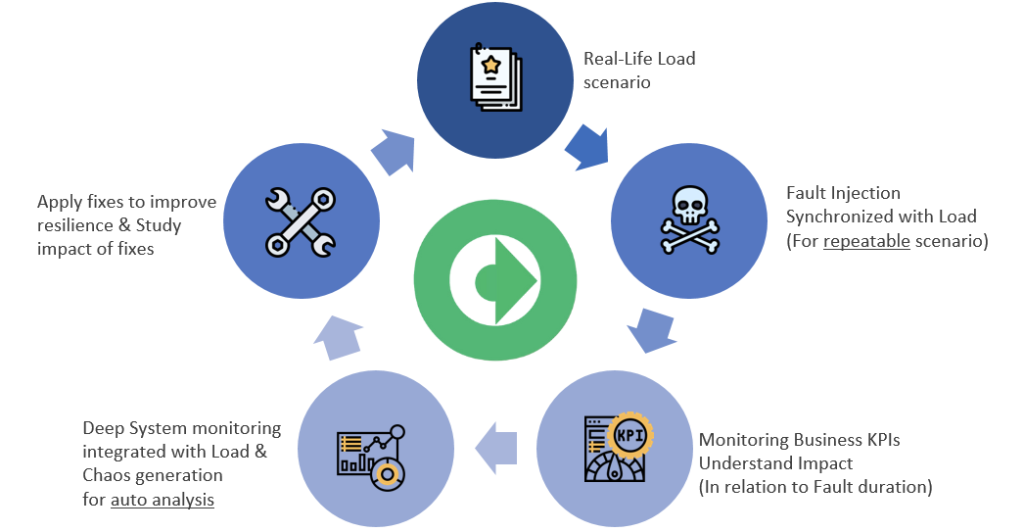
NetHavoc is a chaos engineering tool, which allows users to test the resilience of mission critical applications. You can inject havocs(s) or chaos experiments across the entirety of your application landscape. The after-effects of the fault injection can be monitored through NetHavoc’s powerful monitoring capabilities.
Elevating Resiliency Testing to Resiliency Engineering
NetHavoc gives organizations and teams the ability to conduct chaos experiments in conjunction with production level traffic and extensive observability capabilities across application, user sessions, logs and infrastructure. Traditional methodologies of calculating resiliency scores with negligible observability insights and without production level load falls way short of accurately depicting your mission critical application’s resiliency and often paints a rosy picture whereas the reality might be far from it.
Types of Faults
Various havoc and havoc category name can be developed in an application during its run. These include:
- Bring down application node/server(s)
- Terminate critical processes
- Impact server resources (high CPU, memory, disk space, disk failures, etc.)
- Network level faults
- Application level faults.
Click here to learn more about our full extent of supported chaos experiments or havocs.
Key Features
- Havoc can be injected in production and/or staging environments and the after-effects can be monitored using NetHavoc’s powerful analytical capabilities.
- Havoc can be injected by the Fault Injection software based on different parameters including:
- Time (off hours)
- Probability (of the fault occurring)
- Spacing (between two faults)
- Partial fault (disable network interface) to full fault (server power down)
- Havocs can be injected across the entire application ecosystem, from infrastructure, network, application and message queue level.
- In-built integration with Cavisson’s service virtualization, performance testing and observability solutions provides an end to end platform for increasing resistance against failures.